A Welcome Change of Pace!
I'm very proud to say that, at last, I have made some concrete progress on this project! Since my last blog post, I've managed to not only start to develop the system to render a level, but also pretty much complete it—at least an iteration of it. In its current state, it is able to read a string of instructions to create a set of closed shapes (tracks) made up of corners joined together by connectors. This is more than enough to proceed with other aspects of development, but in the future I'll need to tweak and further develop this system to also parse instructions for where to place enemies and where to spawn the player.
This process involved a fair bit of scope creep, which somehow ended up working in my favour. Initially, the plan was simply to build the tools to render a single track. Each track consists of a set of corners and connectors, which, when rendered to the screen, form a closed loop which the player will be able to navigate. I also initially planned on making this system work using commands similar to Python's "Turtle", as I figured this would be the easiest way to resolve what kind of corner to use for each instruction, but I ended up going with a slightly different approach.
Parsing Level Data
The first order of business was figuring out how to store level data. As I mentioned in my previous devlog, this kind of thing would be trivial in a high-level object-oriented language... but in a low-level procedural language like C, you can't throw the word "trivial" around lightly. Naturally, the best place to start for something like this is to make a struct, which seems easy enough! Let's begin by declaring a utility struct for vector data, that way positions can be stored as a single vector_int (or vector_float, if necessary) instead of a pair of ints (or floats).
// Utility struct to store a pair of x and y coordinates
typedef struct vector_int;
Easy! For some reason I didn't think of doing this earlier, so I went back and updated my corner and ball structs1 to use vector_int structs instead of pairs of ints.
Since I already went over my corner struct in a previous devlog, I'll skip over that. I have also made a connector struct which is likewise very simple, but—unlike the corner struct—this struct is a lot more important. I initially created the corner struct as a way to wrap my head around structuring a program in C, and because I figured they'd be useful at some point in the future, but in practice they serve very little purpose as of now. Conversely, connector structs are immediately crucial: corners, are rendered by simply calling pd.sprite.updateAndDrawSprites(), which will automatically render any LCDSprite I created/registered when building a corner, without me having to provide any parameters. On the other hand, connectors are drawn using pd.graphics.drawLine(), which requires that I pass the start and end coordinates for each connector as parameters every time I want to draw them. This becomes a lot simpler when that data is stored in one single, tidy struct:
// Stores the coordinates for drawing the line connecting two Corners
typedef struct connector;
Finally, we just need a struct to store the data for each track. Well, we already know how to work with structs so this should be pretty easy, right? Wrong! Here's where things get complicated.
A Pointer... To a Pointer?
The thing about structs (from my admittedly limited understanding) is that they must have a constant, clearly defined size. This is something you don't even have to think about for the structs we just described: a vector_int struct can only contain two ints (and the value of an int doesn't affect its size), each being made up of four bytes2, meaning one vector_int struct has a size of eight bytes. A connector struct is made up of two vector_int structs (eight bytes each), meaning each connector struct is just sixteen bytes. The struct for a track, however, is a little more complicated.
Since any one track struct can be made up of an arbitrary number of corner and connector structs (which I call the number of segments), its size must, in theory, be variable to account for more/less pointers for each corner/connector struct we want to store. But since the size of our struct needs to be fixed, we need to find an alternative solution. That's where pointers to pointers come in.
That's right! If pointers weren't already enough to give you a headache, we now have pointers to pointers, so you can pointer while you pointer. Outdated memes aside, pointers to pointers (apparently also known as double pointers) are actually pretty smart and useful—if you can wrap your head around them, that is (I know this is probably a rather simple concept for someone that thoroughly understands memory management and whatnot, but it actually took me a bit to make sense of them). With a double pointer (pointer² maybe?), we can define our track struct as follows. Each double pointer only needs to be big enough to fit one pointer, and then the address that that pointer points to can be of any size (within reason). Since they point to memory outside of our track struct, we don't need to know the size of those external addresses when allocating memory for our struct, as they won't affect the size of the track struct itself.
// Tracks are a collection of Corners connected with Connectors
typedef struct track;
Here's a little visual aid to better explain how this works:
| Address | Content Type | Value |
|---|---|---|
| 0x00 0x01 0x02 0x03 | int segment_count | 4 |
| 0x04 | corner **corners | 0x38 |
| 0x05 | connector **connectors | 0xEE |
| [...] | [...] | [...] |
| 0x38 | corner *corners | [Pointer to a corner struct] |
| 0x39 | corner *corners | [Pointer to a corner struct] |
| 0x3A | corner *corners | [Pointer to a corner struct] |
| 0x3B | corner *corners | [Pointer to a corner struct] |
| [...] | [...] | [...] |
| 0xEE | connector *connectors | [Pointer to a connector struct] |
| 0xEF | connector *connectors | [Pointer to a connector struct] |
| 0xF0 | connector *connectors | [Pointer to a connector struct] |
| 0xF1 | connector *connectors | [Pointer to a connector struct] |
This table shows that memory addresses 0x00 to 0x05 are allocated for a track struct. We can see that, no matter what, the size of a track struct in memory will always be 6 addresses (in this case, 6 bytes, or 48 bits)3. Separate from the memory we have allocated for our track, we can allocate some memory elsewhere which will be referenced by our corner **corners double pointer—in this case, the address it points to will contain 4 pointers, stored between 0x38 and 0x3B, to each of our corner structs. The same is done for our connector **connectors double pointer, but this time with the addresses 0xEE to 0xF1.
This is one of a few things that I researched and implemented since my last blog post that just worked. First try. No issues whatsoever. Crazy, I know. I was expecting this to be a huge roadblock given how difficult it was for me to fully grasp the concept of double pointers, but it ended up being fairly simple, which I think confirms that my understanding of double pointers has improved significantly since I began to learn about them!
This same idea was used for the level struct, which contains an array of track structs and the (currently unimplemented) player spawn location. In the future, this will also contain an array of enemies and whatever other data I may end up needing to store for any given level (score thresholds for gold/silver/bronze? a level title/name, perhaps?)
typedef struct level;
Parsing Individual Tracks
Now that we have a place to store level data, we need to implement a way to actually populate that level data. I initially intended on creating a set of commands similar to Python's turtle commands, but I realized that for each instruction, I'd have to use the current status of the "turtle" to determine what each instruction is supposed to do, which I found to be inefficient. Instead, I decided to use a system consisting of a cardinal directions (north, east, south and west) paired with a distance.
At first I figured I'd have each instruction consist of a letter corresponding to each direction (N, E, S, W), followed by a number (so each instruction would be something like E12, N4, W312, etc)... but to allow multiple digits, I'd have to create a system to read one direction char and then parse the following n chars as a single int, which sounds complex, and more complexity means more room for error. But then I came up with a clever4 workaround!
While figuring out a solution to this dilemma, I realized that a char is nothing more than a (really small) int! The maximum value of an unsigned char is 255 (or ±127 if signed), which I figured I could read as a game grid coordinate (each 32px² sprite is as big as one unit on the game grid) instead of a coordinate on the Playdate's screen, so that should be plenty. And if I ever end up wanting to make a level that's bigger than this... that'll be future Jayde's problem! So, I'll just read one char as a letter corresponding to the direction, and the next char's raw numerical value corresponds to the distance to the next corner.
With that idea in mind, I set off to write a function that takes a string, and parses each pair of chars together. The first char pair is read manually as a number to get the starting position coordinates, and each subsequent char pair is iterated over in a loop, using the first char as the direction of travel and the second as the distance to travel. Feel free to skip this giant codeblock if you don't care about the nitty gritty 😅 but it's thoroughly commented for enhanced legibility!
track*
This function, again, seemed to work perfectly on the first try!5 By golly, two in a row, and after the disaster outlined in my last devlog? I sure hope things continue moving at this pace.
Learning Octal, Apparently?
My amazing idea to parse the distance char as its literal numerical value was working great, with one small caveat. When testing this function, I found out I could insert any number in a string literal by using an escape sequence which, I though, used the decimal numerical value for that character. This is even more useful when you consider that ASCII values between 0 and 31 correspond to unprintable ASCII control characters—meaning they're technically not characters in the traditional sense—so you can't just enter the character that corresponds to whatever number you want. Fortunately, escape sequences can be used to enter these special characters in string literals.
This was all fine and dandy until I tried to call f_level_track_build() using the string "\02\02S\04E\08N\04W\08" (start at (2, 2), then go south 4, east 8, north 4 and west 8). For some reason, only the first bit of the track gets built until it reaches the 2nd instruction. This would've been a super esoteric logic error if it wasn't for CLion's syntax highlighting subtly hinting towards the problem: for some reason, in the second instruction instruction ("E\08"), only the first character after the escape character was being parsed as an escape sequence, resulting in '\0'—aka a null terminator—being placed in the middle of the string.

Since this string contained a null terminator somewhere before the end of the string, C interpreted that as the premature end of the string. This was an easy enough problem to find, but the cause was still a bit unclear. For a while, I thought maybe you're not supposed to use ASCII control characters in a string, and maybe '\08' (Backspace) and '\09' (Horizontal Tab) were particularly illegal characters. Eventually, I realized that these escape sequences use numbers in octal67 instead of decimal, which is why only digits between 0-7 could be used in escape sequences. Trying to use 8 or 9 in octal would be akin to trying to represent the numbers 11 or 12 with just one digit using Arabic numerals8. Never for a moment did I think I'd somehow find myself having to use octal of all things. Hexadecimal? Sure, maybe. Binary? Of course. But octal??? This project is making me go down paths I never thought I'd even glance at...
Anyways, once I figured this out, it was smooth sailing again. Though it does take me 10× longer to manually enter instruction sets containing distances greater than seven, since I then have to mentally calculate the octal value for the number I want to enter. Of course, once this project gets to the point where I have to design levels, I'll write a tool or something to make the process of writing these instructions more intuitive (it might even have a nice UI!)
Splitting the Level Data Into Tracks
Once I had this system working, I figured why not go the extra mile and implement the last bit of functionality necessary to load level data (this is that scope creep I mentioned). This last function is meant to take a string of instruction-sets and split it up into individual tracks, each of which is then fed into the f_level_track_build() function. At first I figured it would be trivial, as all I'd have to do is split the instruction-set into sub-strings separated by an aptly-named separator char. Except, as I mentioned earlier, the word "trivial" should not be thrown around lightly when it comes to C.
After creating a method header in the corresponding header and source files, I quickly came to a harrowing realization: C obviously doesn't have a String.Split() function like C# does, so I'd have to write my own function to separate the string9. Moreover, I realized I'd once again have to deal with double pointers, since strings are just arrays of chars.
I began to implement this function but kept running into all sorts of logic problems—mostly segfaults—and eventually decided to backtrack and rethink my approach. Eventually, I realized I didn't really need to store each substring in an array—I could just iterate over each char, store them in a buffer10, and then send whatever was in the buffer into my track builder function when a separator is encountered, instead of storing it in an array. Then, before starting the next loop, I reset the index for the buffer to start at the beginning, thus reusing that memory and replacing the previous substring, since it has fulfilled its purpose.
Ironically, the escape-character incident that caused the mysterious null-terminators in the middle of a string earlier taught me an important lesson: I can essentially trim any characters after n chars by placing a null terminator at n+1. This can be a little risky, since functions like strlen() will return the string length up to the null terminator, which will be less than the amount of memory allocated for that string if the null terminator isn't the last character in the string. While issues can potentially arise if I don't know the "true" length of the string (i.e., the total memory allocated, as opposed to the number of chars until the null terminator), it's not a problem as long as I store the size of this address so I know how many chars can fit in that string.
All of this is relevant because, as I'm recycling the buffer memory, I'm potentially leaving extra characters after the end of the string, which are only there because the previous buffer was longer than this one. This can be solved by just setting the final character in the string to the null terminator, ensuring nothing will try to read any characters past this point. For example:
// 12 chars are allocated for buffer
buffer = ;
// Result after setting each char in buffer to "Hello World!"
buffer = "Hello World!"
// Result after replacing each char in buffer with "Foo"
// Since the new buffer "Foo" is shorter than the last, the extra characters remain
buffer = "Foolo World!"
// Result after replacing each char in buffer with new buffer "Foo", and then adding a null-terminator after the final char
buffer = "Foo\0o World!"
// Doing this will result in everything after the null-terminator being ignored
; // Output: "Foo"
With this quirk in how strings and null terminators work in C now being put to good use, I was able to implement a function that reads in an instruction-set string, and then passes each track instruction sub-string to the f_level_track_build() function to build out each track in the level. Now, we can just feed it some instructions, and...
We've got some beautiful... corners? Where's the rest of the track?
Drawing the Connectors
As I mentioned previously, drawing the connectors between the corners is a bit more complicated than drawing the corners themselves. The corners are drawn using LCDSprite structs, meaning once I call pd->sprite->addSprite() and pass the corresponding LCDSprite, I can simply call pd->sprite->updateAndDrawSprites() and all corner sprites will be drawn automatically. Connectors, however, are drawn using pd->graphics->drawLine(), which requires passing a start and end position for each individual connector when the method is called. That means that, on each frame update, we must loop through each track in the level, then loop through each connector in that track, and draw that connector manually:
for
for
;
To make things a little less convoluted, I defined a function called f_level_track_connector_draw() which takes a single connector struct and draws that connector's line using its start and end vector_int structs:
void
Now, if you did things correctly, this will simply draw a line between every connector struct's start and end positions. But if you did things like me, you'll (eventually) realize that the code for generating each struct is missing one crucial step:
track*
While I did calculate the value of segment_count, I never actually stored that value inside the new_track struct! As far as my code knows, every struct has zero corners and zero connectors, so the loop would start... and immediately end, resulting in no connectors being drawn (and since corners aren't drawn manually in a loop, I didn't run into this issue earlier). After having a mini heart-attack from thinking something had gone wrong with the double pointers, I eventually realized this tiny, simple omission was the reason none of the connectors were being drawn. Once I cleaned up this error by adding the line new_track->segment_count = segment_count;, I finally had full tracks being drawn!
Debug Camera
At some point during the development of the level building function, I realized it would be quite difficult to test things out if I could only see the small part of the level that fits on the screen. I contemplated writing a function to let me move the "camera" around, but I wasn't sure if this would be wise, as I figured it would be a large endeavour. I'd probably have to create a global "offset" function, then go to every line of code that uses location data and apply this offset—not to mention I'd have to deal with all the issues that this would inevitably produce... until I realized that the Playdate API has a life-saving function for this exact purpose!
Using the setDrawOffset() function included in the API, I can simply pass a single an x vector_intint and y int, and the Playdate will automatically draw everything with that offset. I'll be honest, given how much of a life saver that function is, I might actually change my tune about the Playdate API...
...at least I thought I might. However, any positive sentiment I may have begun to harbour towards the API (or at least the API docs) was quickly eroded. Having figured out how to apply a drawing offset, I needed to find some way of controlling that offset at runtime, and what better way to do this than to use the D-Pad? I figured this shouldn't be too difficult. I already knew that my eventHandler function would be called with the event type kEventKeyPressed and/or kEventKeyReleased whenever a button is pressed on the Playdate. After all, this is what the documentation says, right? Well, as it turns out, what the docs say and what the API does isn't necessarily one and the same.
After a bunch of troubleshooting, adding logToConsole() calls, using the CLion debugger, etc., I eventually found this neat little detail on the Playdate Developer Forum that revealed that the official documentation is actually completely wrong. Instead of listening for calls of my eventHandler function, I'm supposed to call the getButtonState() function instead.
The documentation does have a (tiny, not very informative) section on the getButtonState() function. While the documentation on this function does include a list of... values(?) for PDButton, it makes absolutely zero effort to inform users of how this is meant to be used. Eventually, I figured out PDButton is an enum (I think?) which contains a few elements, each of which functions as a bitmask11 for each button on the Playdate. You're then supposed to use bitwise operators to compare the output bitmask from getButtonState() to these enum bitmasks to determine the state of any button:
int *current_buttons = 0;
pdsys->;
if
In the snippet of code above, I first declare an int pointer called current_buttons and pass this pointer into getButtonState(), which will store the bitmask that represents the currently pressed buttons in current_buttons. With this bitmask now at our disposal, we can use the & bitwise operator (known as a bitwise AND operator) and the values in the PDButton enum to determine the state of any button. In this case, the two operands we'll run through an AND operator are current_buttons (which we obtained from getButtonState(), the value of which is variable) and kButtonUp (which, if you dig through the pd_api_sys.h header file, you will see has the binary value 00000100). Running these two through a bitwise AND will return 00000100 if the 3rd bit of current_buttons is also 1, or 00000000 if the 3rd bit of current_buttons is 0. This allows us to isolate the value of the 3rd bit, which is the bit that represents the status of the up d-pad button. We can then compare the result of this operation to the original value of kButtonUp with a good ol' == to verify if the up button on the d-pad is being pressed, and adjust our drawing offset accordingly.
Rinse and repeat this process for the other directions to get a d-pad controllable "camera", which we can now use to look around our level and verify that everything is, in fact, working as intended!
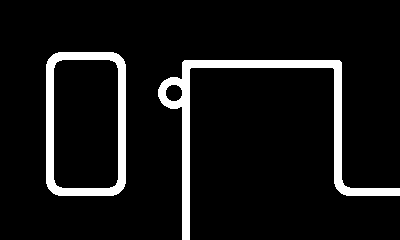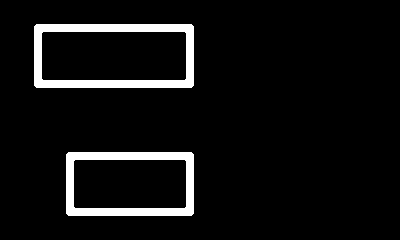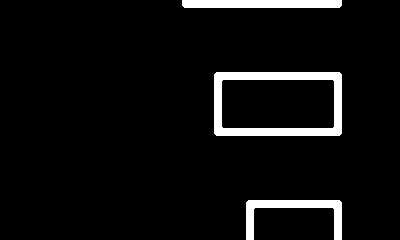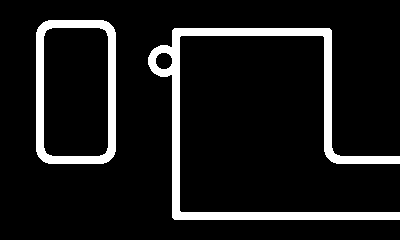
Conclusion
I'm quite pleased that this devlog actually has some solid progress! When I got the instruction-set string parsing function to work, I was filled with that sense of fulfillment one gets when something works, which I haven't felt in a while. I hope this feeling becomes a little less uncommon as things continue to move forward.
Shooting Myself in the Foot(note)
I also took a bit longer than I had planned to get this devlog out. All the code I talk about in here was written on the 10th of May (13 days ago, at time of writing. You can check the commits if you don't believe me!) I figured I'd be able to just do my usual word-vomit in Obsidian, get a devlog out within a couple days, and move on. But Obsidian had other plans...
I recently found out about footnotes and, as you can see from this devlog (and my writing style in general), I immediately began to use and abuse this Markdown feature. To make this process easier, I installed a community plugin called Obsidian Linter (or just Linter), which has many cool features, including re-ordering your footnotes so they're numbered in order of appearance. Unfortunately, I got a little overzealous with my footnote-ing, and eventually caused Linter to break. Without realizing, part of my misuse caused Linter to delete some of my footnotes, and I ended up wasting a bunch of time trying to find the root cause, as well as having to re-write a bunch of footnotes and other esoteric errors that popped up in the process.
I want to make it clear that the problem arose when I tried to add a footnote inside a footnote (I think "overzealous" might be underselling my use of footnotes), so this isn't something I'm going to blame on the Linter plugin. Additionally, I did make a GitHub issue about the one reproducible problem I encountered, and this ended up being the first time an issue I submitted on GitHub didn't just result in it being closed due to inactivity! So huge thanks to Peter Kaufman for responding and giving me an excellent solution almost immediately.
Another issue (this time caused by Obsidian itself, not a plugin) was that some footnotes would randomly be interpreted as one giant footnote, for some reason. This meant that if footnotes 6, 7 and 8 got "merged", I couldn't link to footnote 7 nor 8, since Obsidian wouldn't recognize them as footnotes (it would just think they're plain text, part of footnote 6). I couldn't figure out a cause for this behaviour, but I did eventually find out that adding empty lines between each footnote would fix this problem (although the Obsidian docs indicate that footnotes aren't supposed to have these blank lines between them, so this seems to be a workaround, more than anything.)
I eventually managed to re-write most of the footnotes, implemented the solution I was given on GitHub for the merging issue, and significantly reined in my use of footnotes (you know things were out of control when this is what reined in looks like.)
Anyways...
I managed to finally get this devlog done, which means I can finally move on to whatever's next. I think I might begin working on getting the ball to move along a track. And... due to the Obsidian-related setbacks, this devlog is once again coming out on the 23rd of the month. As I said last time, I do not have any sort of plan or schedule to release each devlog on the 23rd of the month, it just keeps on happening. Kinda spooky... But as long as things keep moving, I can't complain!
Footnotes
I am lying to you. While I did go back and update my corner struct to use a vector_int struct to store its location, I didn't think to update my ball struct until writing this post. An apology video, with tears, will be uploaded to my YouTube channel shortly.
Listen, I KNOW the amount of memory allocated for each datatype can technically vary depending on the compiler and/or platform. Outright saying that the size of an int is four bytes is technically wrong, in that this isn't necessarily true and shouldn't be taken for granted. And to that I say: I don't care... Facetiousness aside, I am aware of this, but for the sake of simplicity I'm just saying an int is four bytes for this example. In practice, I do use sizeof(int) when necessary. In addition to all this, this game is being developed for the Playdate, so in theory the game will always run on the same hardware and OS/firmware. You could assume all instances of this game will have the same size for ints, but... you probably still shouldn't, so I don't 😉
Some more clarification on this memory table: ints are still four bytes in size (hence int segment_count taking up four addresses). Additionally, this hypothetical computer system only has 255 bytes of memory—meaning pointers are only one byte in size, and therefore only occupy one address. This is because the largest possible address in this system, 255 (or FF in hexadecimal, which is how addresses are typically represented), can be represented by eight bits/one single byte. In real computer systems, this is rarely (if ever) the case (though if you know of a computer system with only 255 bytes of memory, do let me know. That'd be crazy.)
If you don't understand why "clever" is a no-no word, you should read my previous blog post, "Structuring a Project Without OOP"!
Foreshadowing is a narrative device in which a storyteller gives an advance hint of what is to come later in the story.
Since apparently some people don't know this: octal is another name for base 8, like how binary means base 2, decimal means base 10, and hexadecimal means base 16.
I'm afraid I went down such a rabbit hole that I ended up with so much tangential information that I needed a second footnote: While researching, I found out that octal can be written as sets of three binary bits. This isn't all that interesting on its own, but then I also found out that the bagua, which I've seen here and there but never knew much about, is exactly that: a set of eight trigrams, each of which consists of three lines which can be broken or unbroken. These lines are, essentially, bits (read from top to bottom, with an unbroken line representing a 1 and a broken line representing a 0). Each trigram can represent a value between 0 and 7, meaning these trigrams are practically a set of symbols that represent a base 8 number system! Though as far as I understand, this was never their intended purpose. Anyways, I just thought that was a neat connection to something I though to be completely unrelated, which I've been somewhat curious about before, but which I never looked into on my own.
Since Arabic numerals cannot represent numbers above 9 in a single digit, but hexadecimal numbers go up to 15, hexadecimal numbers must make an exception and use letters (A-F) to be able to represent numbers between 10-15 in a single digit.
Soon after I began writing this function, I found out that the string.h header file contains a strtok() function for this exact purpose. However, I had already begun to write my own implementation. Additionally, since I was already having trouble getting this function to work by that point, I figured there was something I didn't quite understand yet—and therefore something I'd hopefully learn once I succeeded in implementing my own version of strtok().
This buffer would also technically need to have a variable size, as each substring could be bigger or smaller than another, but I realized any one substring can't be bigger than the size of the instruction-set string that was passed into the function. Thus, I decided to allocate enough memory for the entire instruction-set string for this buffer, and then simply reuse this buffer each loop. This way I wouldn't end up allocating a ton of memory in each loop, only once at the start of the loop.
As irritated I am by having to decipher the functionality of the getButtonState() function, with absolutely no help from the docs, bitmasks are actually pretty cool! From what I gather, they're just plain ol' ints, except instead of interpreting the binary value as a single decimal number, you instead use the raw bit values as—in simple terms—a list of booleans. This is absolutely perfect for something like the return value of getButtonState(), since it can store any permutation of buttons being pressed or depressed released.